This page describes how ExecuTorch works and its key benefits.
How does ExecuTorch work¶
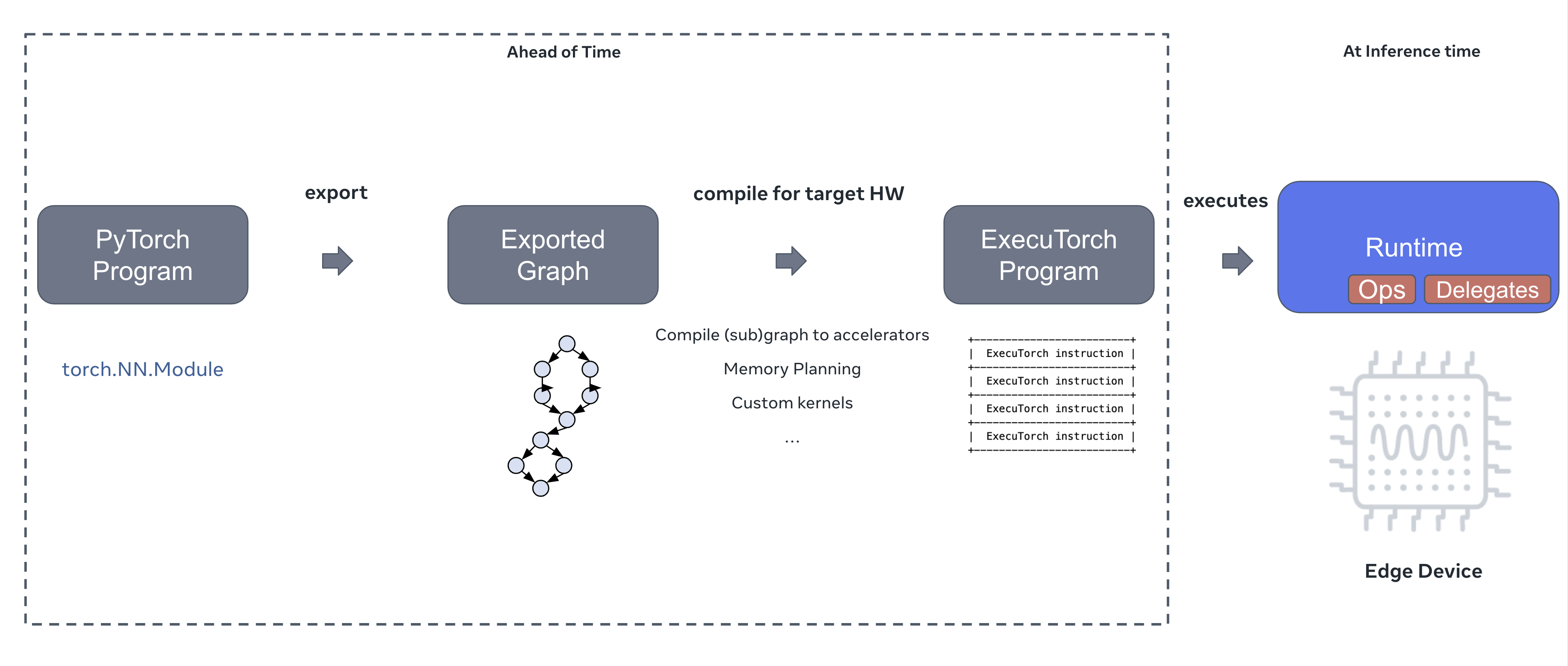
At a high-level, there are three steps for running a PyTorch model with ExecuTorch across edge devices, such as laptops, mobile phones, wearables, and IoT devices.
Export the model. The first step is to capture the PyTorch program as a graph, which is a new representation of the model that can be expressed in terms of a series of operators such as addition, multiplication, or convolution. This process safely preserves the semantics of the original PyTorch program. This representation makes it possible to run the model on edge use cases that have low memory and/or low compute.
Compile the exported model to an ExecuTorch program. Given an exported model from step 1, convert it to an executable format called an ExecuTorch program that the runtime can use for inference. This step performs optimizations such as compressing the model (e.g., quantization) to reduce size and further compiling subgraphs down to on-device specialized hardware accelerators to improve latency. It can also efficiently plan the location of intermediate tensors to reduce the runtime memory footprint.
Run the ExecuTorch program on a target device. Given an input–such as an image represented as an input activation tensor–the ExecuTorch runtime loads the ExecuTorch program, executes the instructions represented by the program, and computes an output. This step is efficient because (1) the runtime is lightweight and compatible with embedded devices and (2) an efficient execution plan has already been calculated in steps 1 and 2, making it possible to do performant inference on highly-constrained devices.
This figure illustrates the three-step process of exporting a PyTorch program, compiling it into an ExecuTorch program that targets a specific hardware device, and finally executing the program on the device using the ExecuTorch runtime.
Key Benefits¶
ExecuTorch provides the following benefits to engineers who need to deploy machine learning models to an edge device:
Export that is robust and powerful. Export uses TorchDynamo, the same technology used in PyTorch 2.0 to capture PyTorch programs for fast execution. While eager mode is flexible and allows experimentation in Python, it may not work well if Python isn’t available or cannot deliver efficient execution. The Export Intermediate Representation (EXIR) that export flow generates can describe a wide range of dynamism in PyTorch models, including control flow and dynamic shapes, which makes it a powerful tool for fully capturing existing PyTorch models with little effort.
Operator standardization. During the graph export process, the nodes in the graph represent operators such as addition, multiplication, or convolution. These operators are part of a small standardized list called the Core ATen Op set. Most PyTorch programs can be decomposed into a graph using this set of operators during export. There are two benefits to having a small list of standardized operators: (1) There is a library of operator implementations that are compliant with the Core Aten Op set, and that library can be linked to the runtime, which enables models to run on ExecuTorch without any additional setup, and (2) it is possible to swap out these implementations with optimized third-party implementations or to go through standard compiler passes (e.g., operator fusion) to accelerate performance on specialized hardwares.
Standardization for compiler interfaces (aka delegates) and the OSS ecosystem. In addition to the Operator standardization above, ExecuTorch has a standardized interface for delegation to compilers. This allows third-party vendors and compilers to implement interfaces and API entry points for compilation and execution of (either partial or full) graphs targeting their specialized hardware. This provides greater flexibility in terms of hardware support and performance optimization, as well as easier integration with the PyTorch open source ecosystem for on-device AI.
First-party SDK and toolchain. Due to the above standardization efforts, it was possible to build a unified first-party SDK for ExecuTorch, where developers can export, compile, and deploy to a wide range of target devices–such as iOS, Android, and microcontrollers–using the same SDK, streamlining the process and gaining productivity. Additionally, the SDK provides profiling and debugging functionality to easily inspect intermediate states, which are core parts of most developer workflows.
No intermediate conversions necessary. ExecuTorch’s main design principle is to allow developers to run their models on target devices without the need for converting to third-party intermediate representations. This eliminates a number of problems that on-device developers typically face when working with these conversion steps, such as lack of debuggability and profiling, the need to familiarize themselves with hardware-specific tools, and models not being able to run due to conversion steps failing.
Ease of customization. Developers can optimize their deployment for even better performance gains on the target architecture by applying custom techniques, such as linking with high-performance operator implementations or customizing memory planning based on storage and latency trade-offs. This level of customization is made possible through the standardization of the compiler pass interface and registration APIs on exported graphs.
Low overhead runtime and execution. The ExecuTorch runtime, written in C++, is highly efficient and can run on a wide range of architectures, including Linux, iOS, Android, embedded systems, and bare metal hardware, with little additional setup or configuration. It is capable of linking in only those operators needed for the model, resulting in a minimal runtime binary size. It is also able to run at low latency because of ahead-of-time compilation and memory planning stages, with the runtime responsible only for execution (e.g., call operator
convand save the result in memory location X).
The above highlights the key advantages of ExecuTorch across three main categories: portability, productivity, and performance. We consider it to be an ideal choice for enabling on-device AI across mobile and edge computing platforms.
